Classic Controllers on Pendulum¶
Myriad’s evaluate() API runs any controller — classical or learned — over many parallel
rollouts and returns summary statistics. Before training a learning agent, it is useful to
establish what hand-coded heuristics can achieve.
We evaluate three controllers on the Pendulum swing-up task. The pole starts hanging down; the agent must swing it upright and hold it there by applying torque.
Random: applies random torque — a lower bound on performance
Bang-Bang: applies maximum torque opposing angular velocity (a simple damping heuristic)
PID: a proportional controller that smoothly tracks zero angular velocity
The evaluate() call introduced here reappears in Tutorial 02 when a trained agent is compared against these baselines.
import matplotlib.pyplot as plt
from _helpers import setup_logging, side_by_side_videos
from myriad import create_eval_config, evaluate
from myriad.utils.rendering import render_episodes
setup_logging()
Section A: Evaluate¶
Myriad’s evaluation workflow is two calls:
create_eval_config()— builds an immutable config specifying environment, agent, and evaluation settingsevaluate(config)— runs the rollouts in parallel and returns anEvaluationResultsobject
Agent-specific parameters (obs_field, kp, etc.) are passed as flat kwargs; Myriad
routes them to the agent config automatically.
We run 50 rollouts per controller with return_episodes=True, which captures raw episode
data (observations, actions, rewards) in addition to summary statistics — needed for
rendering videos later.
agents = {
"Random": dict(agent="random"),
"Bang-Bang": dict(agent="bangbang", obs_field="theta_dot", setpoint=0.0, invert=True),
"PID": dict(agent="pid", obs_field="theta_dot", setpoint=0.0, kp=1.0, dt=0.05),
}
results = {}
episodes = {}
for label, kwargs in agents.items():
config = create_eval_config(env="pendulum-control", eval_rollouts=50, seed=0, **kwargs)
results[label] = evaluate(config, return_episodes=True)
# Store first episode for rendering
episodes[label] = {k: v[0] for k, v in results[label].episodes.items()}
print(f"{label}: {results[label]}\n")
INFO:2026-02-23 16:45:09,735:jax._src.xla_bridge:822: Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: libtpu.so: cannot open shared object file: No such file or directory
[16:45:09 INFO] Unable to initialize backend 'tpu': INTERNAL: Failed to open libtpu.so: libtpu.so: cannot open shared object file: No such file or directory
[16:45:11 INFO] Artifacts: outputs/2026-02-23/16-45-09
├── .hydra/ (config snapshot)
├── results.pkl (metrics & config)
└── run_metadata.yaml (timing & status)
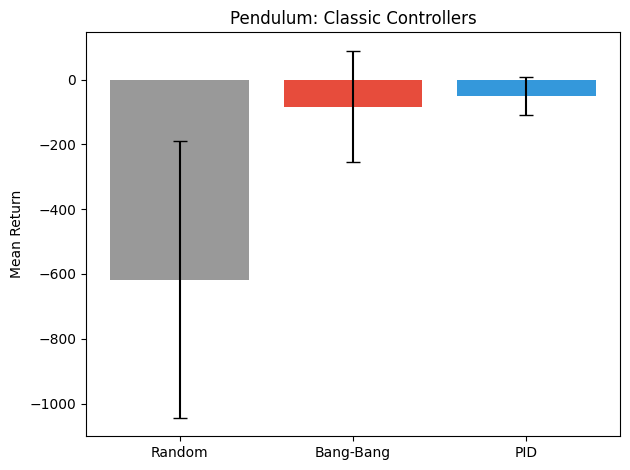
Random: EvaluationResults(
mean_return=-617.4 ± 426.7,
range=[-1415.9, -11.4],
mean_length=200.0,
num_episodes=50
)
[16:45:11 INFO] Artifacts: outputs/2026-02-23/16-45-11
├── .hydra/ (config snapshot)
├── results.pkl (metrics & config)
└── run_metadata.yaml (timing & status)
Bang-Bang: EvaluationResults(
mean_return=-83.3 ± 172.3,
range=[-968.6, -1.7],
mean_length=200.0,
num_episodes=50
)
[16:45:12 INFO] Artifacts: outputs/2026-02-23/16-45-11
├── .hydra/ (config snapshot)
├── results.pkl (metrics & config)
└── run_metadata.yaml (timing & status)
PID: EvaluationResults(
mean_return=-51.0 ± 59.5,
range=[-268.2, -0.3],
mean_length=200.0,
num_episodes=50
)
Section B: Compare Performance¶
The Pendulum reward is always negative: it penalises distance from upright and torque magnitude, so higher (less negative) is better.
names = list(results.keys())
means = [results[n].mean_return for n in names]
stds = [results[n].std_return for n in names]
plt.bar(names, means, yerr=stds, capsize=5, color=["#999", "#e74c3c", "#3498db"])
plt.ylabel("Mean Return")
plt.title("Pendulum: Classic Controllers")
plt.tight_layout()
plt.show()
Section C: Render Episodes¶
Visualise one episode per controller to see the behaviour directly.
video_paths = []
video_labels = []
for label, episode in episodes.items():
agent_name = agents[label]["agent"]
path, _ = render_episodes(
episode=episode,
env_name="pendulum-control",
output_path=f"videos/pendulum_{agent_name}.mp4",
fps=20,
)
video_paths.append(path)
video_labels.append(label)
side_by_side_videos(video_paths, video_labels, width=200)
The Kernel crashed while executing code in the current cell or a previous cell.
Please review the code in the cell(s) to identify a possible cause of the failure.
Click <a href='https://aka.ms/vscodeJupyterKernelCrash'>here</a> for more info.
View Jupyter <a href='command:jupyter.viewOutput'>log</a> for further details.
Key Takeaways¶
evaluate() is controller-agnostic:
The same API accepts classical controllers and trained agents. Myriad runs all of them
over parallel rollouts — 50 here, but scaling to thousands costs minimal extra time.
Baselines set the target:
Even simple heuristics outperform random by a wide margin. Knowing what a hand-coded
controller achieves sets a meaningful target for learning agents — and exposes the gap
that training needs to close.
Next: Tutorial 02 trains DQN on CartPole and uses evaluate() to compare the trained
policy against non-learning baselines, using exactly the pattern introduced here.